
下载温馨提醒:
鉴于电脑系统版本不同,电脑所装杀毒软件不同,电脑自行设置的不同,下载中可能显示无法下载或者停止,这不是系统软件的问题,您可将选择信任该软件或者添加白名单,或者尝试卸载360软件,下载好后在装杀毒软件,这样一般都可顺利下载。如果仍不能解决问题,可联系客服和技术帮忙解决。
客服电话微信:13718871018 技术电话微信:19977391966


原标题:从 AlphaGo 到Master, 最大优势是通用算法
围棋对 AI 的挑战难点在于棋盘空间的大小,它包含10170 个位置状态空间。作为比较,国际象棋的状态空间约为1043。这样的游戏都具有高分支因子,也就是当前状态下的可能下法的数量。围棋中可能的游戏场景的数量要大于宇宙中的原子数。

AlphaGo 的开发者设法解决了这一问题。他们设计的系统基于树搜索,由神经网络驱动。然而,所有这些技术都不是新的,也被其他围棋 AI 的开发者使用。
那么,是什么让 AlphaGo 如此特别?

来自德国和俄罗斯的几位研究人员在《Lessons Learned From AlphaGo》一文中探讨了这一问题。他们在围棋 AI 发展的大背景下讨论了 AlphaGo 的设计。通过展示 AlphaGo 的架构。文章显示出, AlphaGo 实施的每一个细节都是多年研究的结果,而它们的融合才是 AlphaGo 成功的关键。
围棋的历史长达数千年,是一种非常受欢迎的智力游戏和比赛。和国际象棋、跳棋一样,围棋属于完美信息博弈。也就是说,游戏的结果完全取决于两个玩家的策略。这使得从计算角度解决围棋问题很有吸引力,因为我们可以依靠机器来找到最佳的下子策略。然而,由于搜索空间巨大,这一任务非常困难。因此,围棋被认为是AI 的理想前沿阵地,曾被预计在十年内无法实现对人的胜利。
实际上,就在多一年多以前,虽然有许多围棋 AI ,却几乎没有达到人类高手水平的,更不用说与职业棋手相抗衡。然而,在2016 年初,Google DeepMind 发表了一篇文章,表示他们的AlphaGo 能够击败职业棋手。几个月后,AlphaGo 在正式比赛中击败了围棋世界冠军,这是非常重要的事件,因为“大挑战”被完成了。
AlphaGo 的 CNN 的输入部分是当前的棋局,输出部分是对人类对手下一步棋的预测
回想一下,使用神经网络的最初目的是模拟人类在下围棋时的思维过程。AlphaGo 使用神经网络来预测人类对手的下法。基于此,AlphaGo 的CNN 的输入部分是当前的棋局,输出部分是对人类对手下一步棋的预测。
描述得更精确些,即为了训练CNN,AlphaGo 的开发者在围棋服务器KGS 上选取了三万盘棋局,并从每一局中随机抽取对战的位置及棋手随后的行棋。这些应对的行棋就是神经网络预测的目标。
输入位置转换为48 个特征,表示每个交叉点棋子的颜色、四周相邻位置为“空”的数量和一些其他信息。这些特征都根据以前的研究结果[CS15] 进行了选择。
因此,输入层是一个19×19×48 堆栈,包括了棋盘上每个交叉点的每个特征的值。CNN 有13 个隐藏层,每层256 个滤波器。输出层的尺寸为19×19,输出中的每个单元都包含一个人将棋子放在相应交叉点的概率。
神经网络通过标准反向传播进行训练。上述方案代表了一种监督学习方法,因此,我们将由此所得到的网络称为SL 网络。不过,AlphaGo 还使用了强化学习。
神经网络与蒙特卡洛(MCTS)的融合
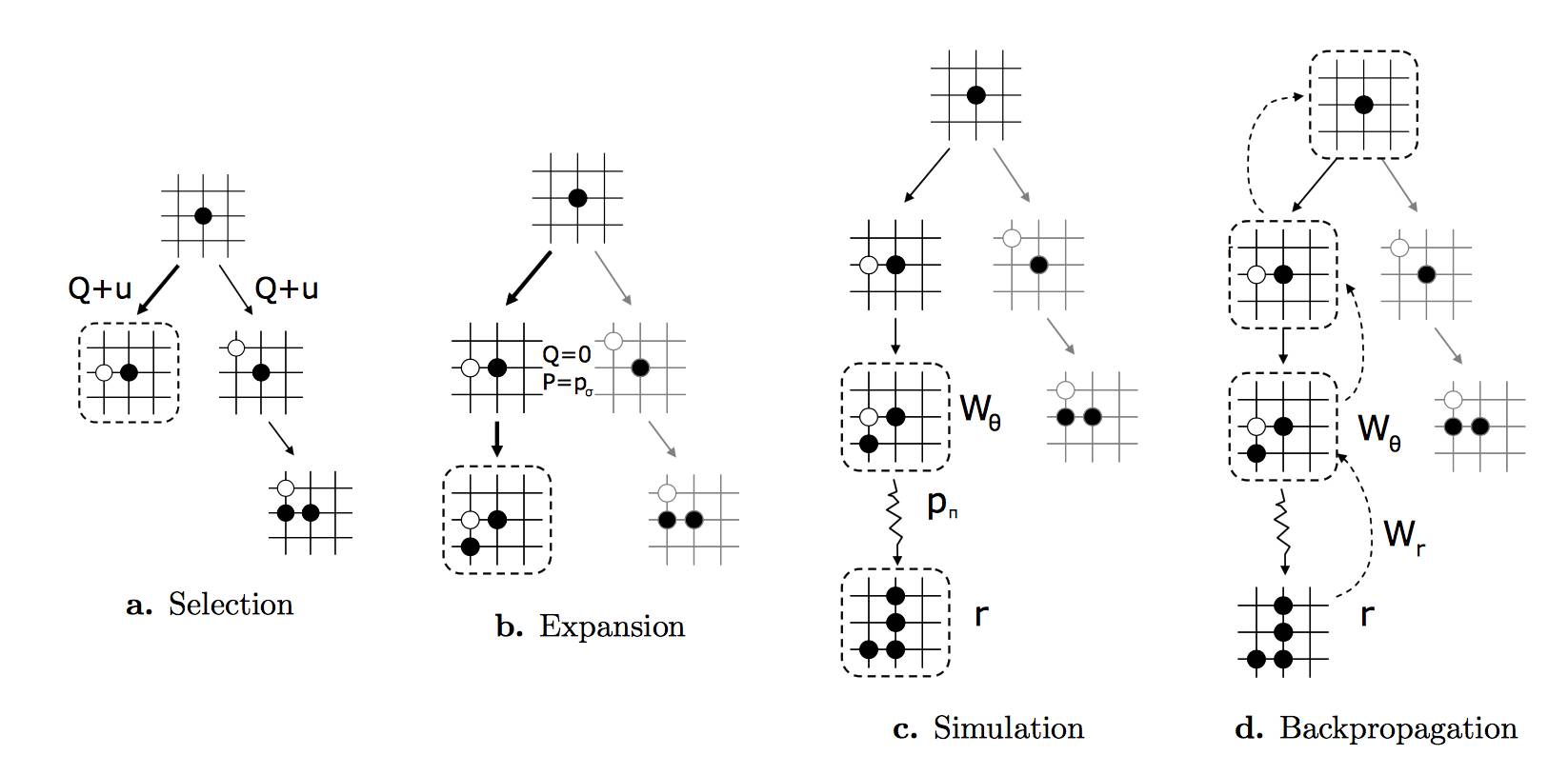
图:AlphaGo中的蒙特卡洛树搜索。在选择阶段,决策主要受到SL网络(a)中得出的概率优先的影响。
AlphaGo 中的神经网络用来干什么?SL 网络在 MCTS 的选择阶段使用,用于鼓励探索(exploration)。一个好的选择规则会对已知走法进行优化,并且探索新的下法。 AlphaGo使用了各种不同的UCT规则来选择行动,优化方程式x(a) + u(a),其中,x(a)是对行动(走法)的评估。u(a) 是P(a) 的一部分,即SL神经网络预测出来的概率。在一个场景中,CNN会偏向MCTS,来尝试新的走法,这些走法一般都是非常罕见的,但是对于CNN来说,却是一个最优解。
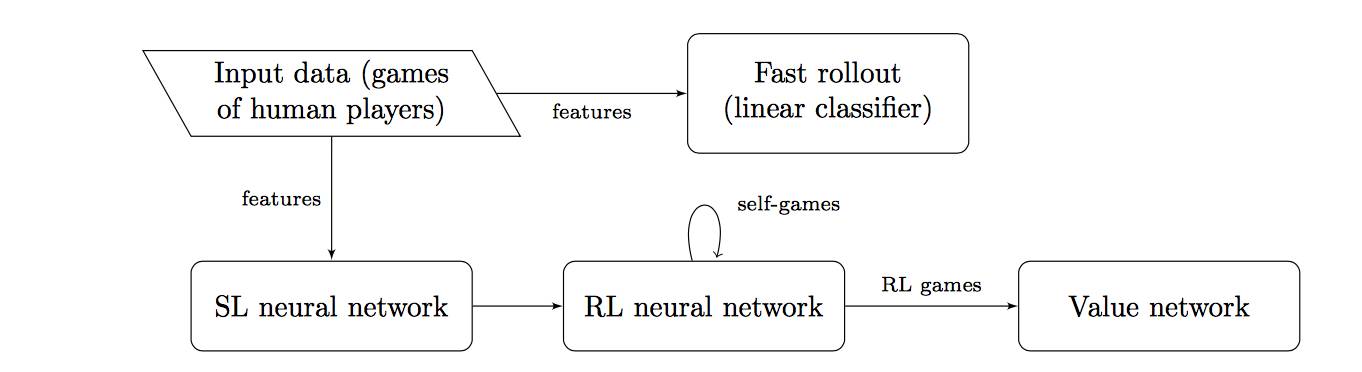
图: AlphaGo中的学习通道。SL 指监督学习;RL 指 强化学习。
虽然增强学习网络被证明比 SL 网络更强,但是,当走法的选择经过SL网络提升时,AlphaGo的整体表现会更好。有这样一个事实可以解释这一现象——SL 网络更像人类,它是经由真实的人类对弈训练的。人们总会倾向于进行更多的贪多,有时是处于对弈中的错误,有时则是因为热情。
虽然如此,增强学习网络在 AlphaGo 的其他部分找到了用武之地。也就是被用于评估价值函数的价值网络。
AlphaGo 最大的优势是应用了通用算法
本文探讨了首个精通围棋这项运动的人工智能 AlphaGo 的相关现象。在此重述们一下相关要点。定义了围棋的规则后,我们解释道计算机通过遍历博弈树从而掌握了这一游戏。然而,围棋的博弈树极其庞大,大到需要应用如 MCTS 之类的统计方法。我们在 MCTS 中加入了几个改进措施,然后就看到 AlphaGo 使用卷积神经网络来进一步加强了 MCTS。
可以说 AlphaGo 最大的优势就是它应用了通用算法,而不是仅局限于围棋领域的算法。AlphaGo 证明了像围棋这样复杂的问题都可以通过先进的技术解决。深度学习已经 被成功应用于图像及自然语言处理、生物医疗及其他领域。AlphaGo 的开发者们所使用的方法或许也可被应用于上述领域。
免责申明:本站所有内容均来自网络,我们对文中观点保持中立,对所包含内容的准确性,可靠性或者完整性不提供任何明示或暗示的保证,请仅作参考。若有侵权,请联系删除。
